我经历的最严重的生产事故中学到的教训
去年五月,我经历了我职业生涯中最艰难的生产事故。整个公司的运营受到了2周的影响,对我的团队施加了巨大的压力。
今天的文章会稍微技术一些。我将分享:
-
出了什么问题
-
我们是如何解决的
-
你如何避免类似事件的发生
-
从中获得的教训
背景
在后端,我们有几个微服务(用Python编写,它们之间使用GRPC进行通信),以及基于GCP的PubSub的事件系统。
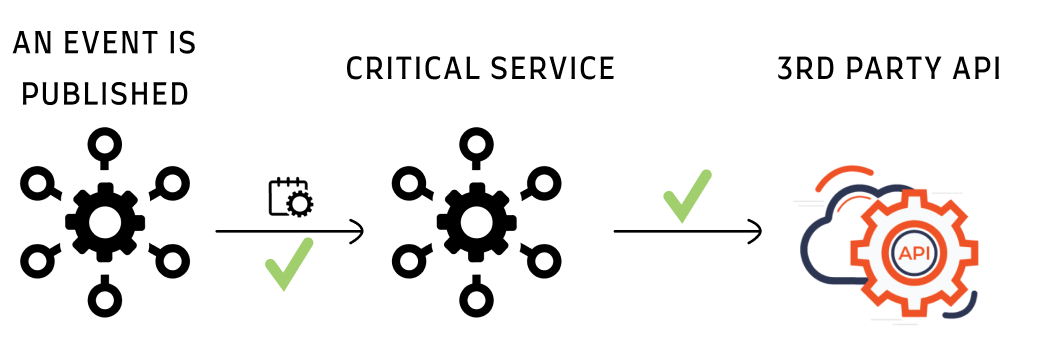
有一个关键的微服务,它依赖一个第三方API。当发布相关事件时,该服务调用API,处理响应,并确认事件。
这是正常流程:
[
{kind=link}
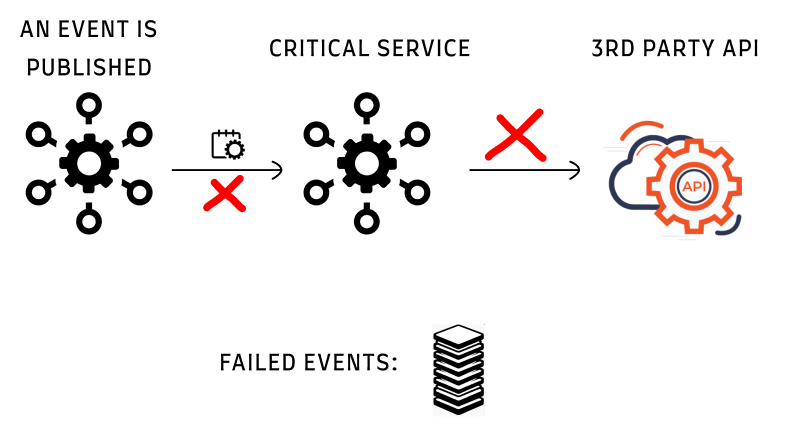
事故原因
有一天,我们开始从该API收到429响应错误。这导致事件处理失败。事件处理不要求实时处理,几分钟的延迟是可以接受的。在这种情况下,我们处理事件花费了几个小时,这对我们的运营流程产生了严重影响。
[
{kind=link}
429响应的示例:
|
|
API有一个限制(仅作为示例,每分钟100个请求),我们第一次超过了这个限制。所以所有额外请求都被丢弃。
要更深入了解速率限制,我建议阅读Neo的文章(
):
处理后果
初始响应
429错误之前,事件随时间变化的图表如下:
[

{kind=link}
我们有一些小峰值的事件,它们被快速处理。
现在,即使针对每个事件进行5次带有退避策略的重试,我们也陷入了困境。我们有数千个处理失败的事件,重新运行它们需要时间(因为在每次重新运行中,一些事件仍未被处理)。
情况如下:
[
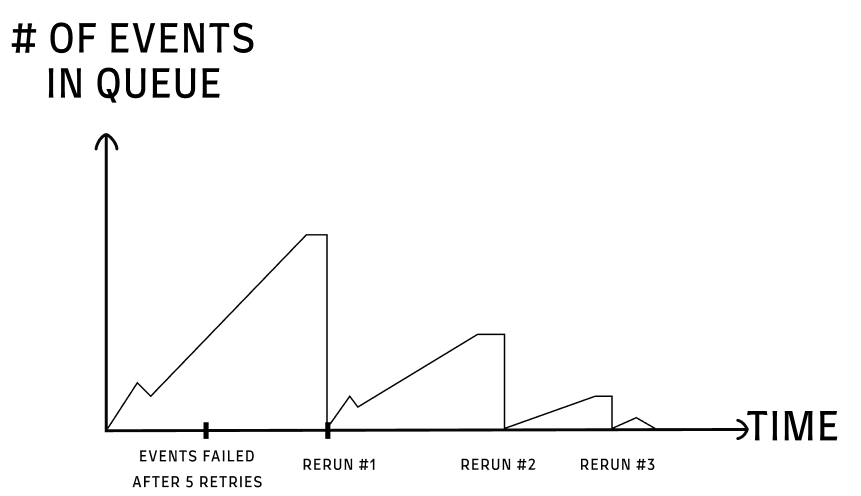
{kind=link}
这需要手动重新运行。 我觉得这是一项“低人一等”的任务,不想让我的团队感到沮丧。
我们本可以自动重新运行,但出于两个原因,我决定不这样做:
-
我假设我们会很快找到解决方法(最多几天)
-
我担心进一步冒险。已经大大延迟导致了其他一些问题,在每次重新运行之后,我们必须进行一些合理性检查。
尝试解决方法
当开发人员达到API限制时该怎么办?
[

翻译 private_upload/default/2023-12-23-10-42-46/How a 3rd Party API Can Ruin Your Weekend.md.part-1.md
{kind=link}
寻找解决方法…
我们以为限制速率是每个 API 令牌的。所以我们创建了多个使用不同 API 密钥的 pod,并在它们之间负载均衡处理事件。
然而却没有得到结果。我们认为可能是每个用户的限制,所以我们从不同的用户生成了新的 API 密钥。
但这种方法也不奏效…
结果发现速率限制是针对整个项目的。为了辩护,文档中没有提到这一点(我们付出了相当可观的费用来使用该 API,所以没有硬限制的假设并不是那么牵强的)。
解决办法
在失败的解决方法上浪费了时间后,我们决定同时采取3个方向:
优化服务的调用
在尝试调试常见事件时,我们发现了两个问题:
-
通过小的逻辑改变,我们可以减少事件数量50%。
-
对第三方 API 的一些调用可以批量处理(5个调用 → 1个调用)
处理429错误的适当响应
在HTTP响应中,“X-RateLimit-Reset”给我们提供了可以再次使用API的时间。在那个时间之前,任何调用都会失败。因此,一旦调用收到429响应,服务将等待到达“X-RateLimit-Reset”才进行重试。
这仍然会导致延迟(因为所有事件都在队列中等待,直到服务能够处理它们),但至少不会有失败(也不再需要手动重试了🎉)。
为此,我们请架构团队立即帮助我们(我们是一家小型创业公司,他们是经验最丰富的工程师)。
提高与第三方 API 提供商的限制
我们意识到即使进行了优化,我们仍然需要在高峰时段提高限制。
如何避免?
依赖于第三方 🔗
这一点很难避免。文档中没有指定限制速率,即使我们与公司交谈,他们也提到他们可以随时更改限制,并且无法确定限制会是什么。
这引发了一个问题,我们是否可以依赖这样的服务,这更多是商业决策而不仅仅是技术决策。
负载测试 🏋️
这完全是我的问题。
人们建议在增长季节开始之前进行适当的负载测试(因为与上一个季度相比,我们的变化很多,包括对该可怕的第三方 API 的依赖增加)。
进行适当的负载测试需要花费我们几个星期的时间,因为我们没有基础设施来模拟100%的真实场景。
我在负载测试中有过不好的经历。由于你正在进行模拟,根据墨菲定律,你在与生产环境不同之处将是稍后出现问题的地方…
经验教训
呼,这是一个漫长的回顾 :)
❌ 分担负载
这次事故突显了我倾向于“庇护”团队的倾向。在整整一个星期之后,我们才建立起一个值班轮班。在此之前,我每天自己凌晨2点之前重新运行事件。
可笑的是,当你试图将团队从“可怕”或“乏味”的工作中庇护起来时,你传达的信息是你不信任他们。只有你才能被依赖。
❌ 依赖手动工作
我决定不自动化失败事件的手动重新运行是错误的。我以为只要几天,自动化的风险不值得。
✔️ 吸纳跨团队职能
架构师和DevOps团队是一个游戏规则的变革者。他们愿意亲自动手,日以继夜地工作帮助。
在像这样同时尝试多种解决方案的情况下,有经验的外部帮助是至关重要的。
总结
-
👀 仔细研究您所依赖的任何第三方API
-
🤝 与团队共享负载(即使是烦人的工作)
-
🔀 当您不确定什么能起作用时 - 同时采取多个方向(即使有浪费时间的风险)
我重新回到之前人们似乎喜欢的格式,分享真实的故事以及我从中学到的东西。回顾起来,我们的一些错误可能听起来很愚蠢 - 我希望这篇文章能帮助您避免类似的错误 :)